Optimizing CNNs and Vision Transformers with Generative Data Augmentation (DiffuseMix)
Deep Learning Optimization with Generative AI
Download the PDF here | View on GitHub
Synthetic data generation is becoming increasingly important in various industries, from manufacturing to robotics. In this post, I’ll walk you through the process of boosting CNN and Vision Transformer performance using DiffuseMix and generative priors to double the training dataset.
Model Architectures
The core of our comparative study consists of three distinct architectural approaches tested on the CIFAR-10 dataset:
- Baseline CNN: ResNet-32 (approx. 0.47M parameters) to establish a strong convolutional baseline.
- Vision Transformers (ViT): Custom implementations of Tiny, Small, Medium, and Large variants (0.8M – 21M parameters) to test attention mechanisms under data-scarce regimes.
- Generative Augmentation: A DiffuseMix pipeline leveraging Stable Diffusion (InstructPix2Pix) and fractal noise to synthesize semantic variations.
Technology Stack & Methodology
We utilized PyTorch for all model implementations and training loops. The project focuses heavily on hyperparameter optimization to ensure fair comparisons.
Optimization Strategy
For the ResNet-32 baseline, we conducted a systematic study comparing:
- Optimizers: SGD (with Momentum) vs. Adam.
- Scheduling: Multi-step decay vs. Cosine Annealing.
- Result: SGD with a learning rate of 0.1 and weight decay of $1 \times 10^{-4}$ proved superior, achieving 87.50% validation accuracy.
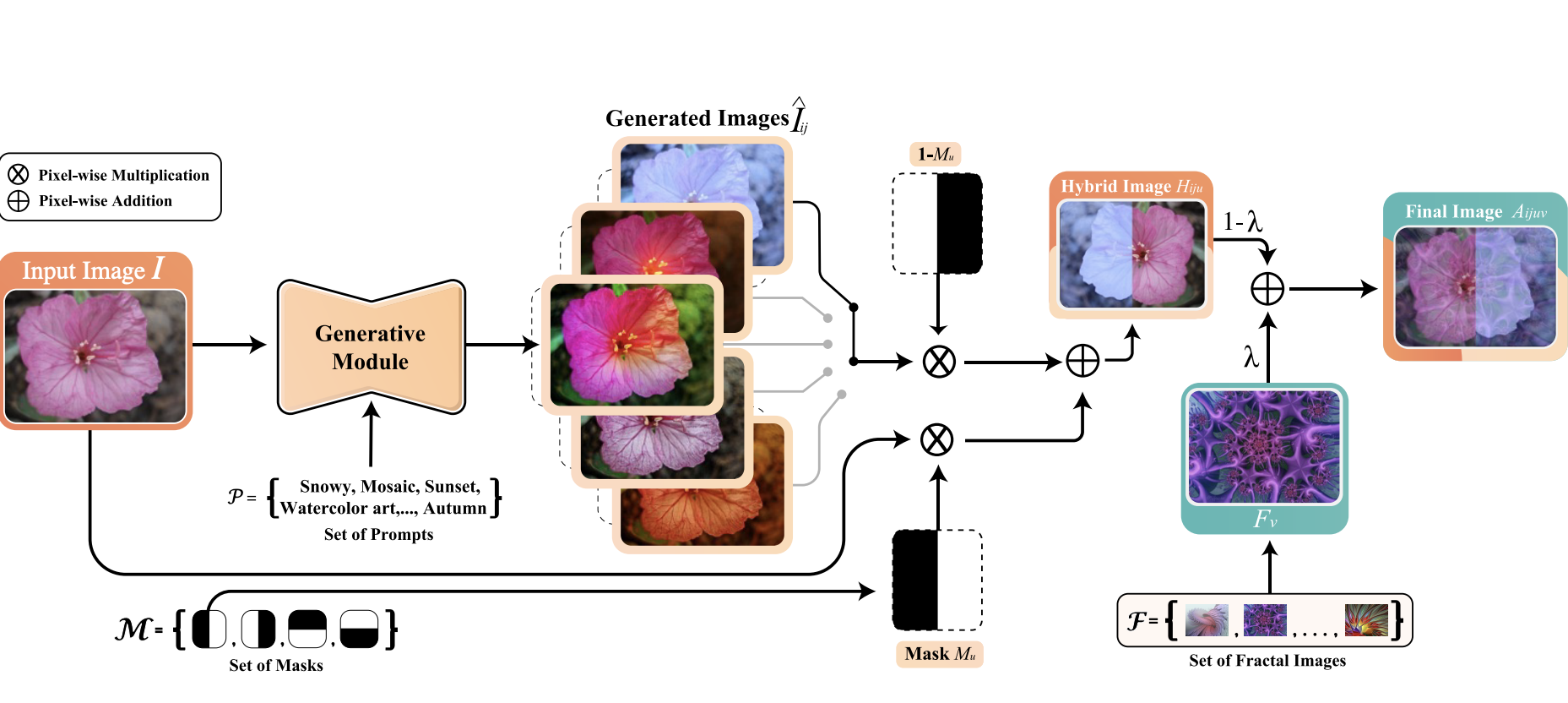
The DiffuseMix Pipeline
To combat the data-hunger of Transformers, we implemented DiffuseMix. Instead of standard geometric augmentations, this pipeline blends original images with diffusion-generated variations and fractal patterns to enhance robustness.
The mixing process combines the original image (x_orig), the diffusion variation (x_diff), and a fractal pattern (x_frac):
import torch
def diffuse_mix(x_orig, x_diff, x_frac, mask, lamb=0.15):
"""
Combines original, diffusion, and fractal images.
"""
# Create hybrid from original and diffusion using binary mask
x_hybrid = mask * x_orig + (1 - mask) * x_diff
# Interpolate hybrid with fractal noise
x_final = (1 - lamb) * x_hybrid + lamb * x_frac
return x_finalResults & Analysis
 Our experiments highlighted a massive shift in performance when using generative augmentation, particularly for the smaller Transformer models.
Our experiments highlighted a massive shift in performance when using generative augmentation, particularly for the smaller Transformer models.
Key Findings
- ResNet-32: The DiffuseMix augmentation pushed our optimized baseline from 87.50% to 88.99% (+1.49%).
- Vision Transformers: The smaller ViT models saw the largest gains. The ViT Medium model achieved a ~8% accuracy boost (reaching 79.29%) when trained on the augmented dataset.
- Scaling Limits: The ViT Large model suffered from severe overfitting, demonstrating that even with synthetic data, massive Transformers require significantly more data or pre-training to converge on small images.
Conclusion
This project demonstrates that while CNNs (ResNet) remain highly efficient for small datasets like CIFAR-10, Generative AI augmentation can significantly bridge the performance gap for Vision Transformers. However, architectural depth must still be carefully balanced against available data volume.